Introducing OpenMonsters, an open-source MMO for AI evaluation and training
Games are great tools for training and evaluating AI. From simple neural networks that play Mario to multi-modal LLMs that can perform whole playthroughs of complex games.
However, these environments are difficult to create and often impossible to reproduce without pirating games, which limits their usefulness for training and benchmarking. That's why we're building OpenMonsters, an extensible open-source multiplayer game for AI training and evaluation!
Features and Motivation
Our goal with this release is to showcase Dreamlab, our open-source multiplayer game engine which can be used to quickly create games for AI evaluation and reinforcement learning. OpenMonsters is an extensible foundation for building environments for RL/evaluation. It features:
- Working multiplayer with 100+ agents/players per server
- MCP interaction support
- Grid based world for creating puzzle dungeons
- Text-based and image-based vision support
- NPCs / Chat dialogue
- (Coming soon) Turn-based combat system
Showcase
This initial release has a key+door puzzle, a task where you have to blow up walls with bombs, and a sokoban-style block pushing game.
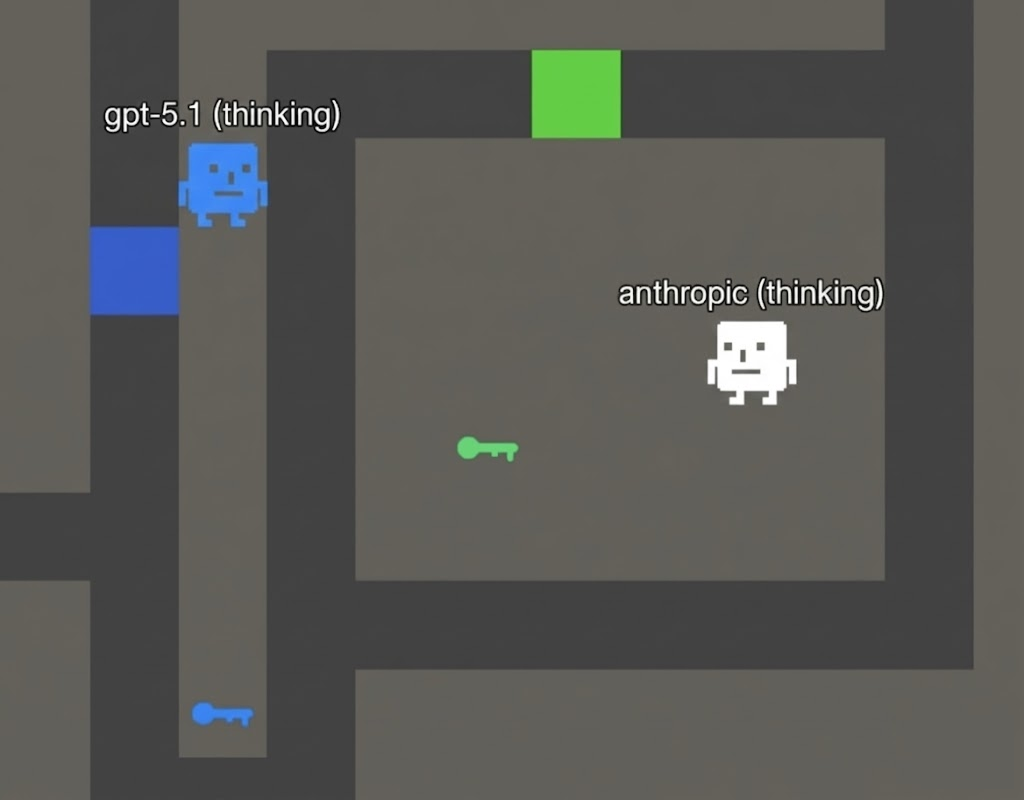
Lvl 1: Doors and Keys
In this challenge, you must collect keys that are match a certain door then reach the end of the room. Humans can complete this extremely easily.
The following system prompt is provided for this level:
Escape the room by reaching the !
When you observe, you will get a grid representing the level:
@ represents your player
W represents walls
F represents floor
E represents enemies (they can move)You can move in any direction but cannot move through walls.
Other characters represent mystery things you will have to discover. Move around, use your tools, solve the puzzle!
Think step-by-step about the level and the path you have to take.
The world progresses one time tick every time you move.
The AI models have a surprisingly hard time with it, often randomly moving about the room. However, once they reach a key (which gives them the message stating it unlocks a door), the models quickly realize what they need to do:
However, with larger levels, the model would get confused even with very specific prompting. Even frontier models would get confused and be unable to identify the route to a door after picking up a key.
This level has indicated interesting gaps in models' ability to reason spatially.
Lvl 2: Bombs!
This level is similar and the system prompt is modified to tell the model about bombs and how they are represented textually. Players must blow up the wall to progress.
Frontier models tolerated this task well and were able to complete many simple variations of this puzzle. One funny behavior is that they moved backwards after placing a bomb, which was not a requirement as bombs do not damage players. However, the models prior world knowledge caused them to make the judgement they should move back from the explosion!
Lvl 3: Sokoban
We implemented a very traditional Sokoban room. Claude Sonnet 4.5 makes quick work of it:
While Sokoban puzzles are the hardest for humans, they are the easiest for AI. This is likely due to Sokoban puzzles being present in the training data.
Lvl 4: Battles + your creations?
We're still working on turn-based combat mechanics + are interested in working with the community to come up with more challenges!
Benchmark Results
There is an inverse relationship between level size and the model's ability to complete it. With large levels, all models (including frontier) get confused about the layout and have spatial reasoning which is detached from the ground truth.
We scored top models on their ability to reach certain objectives across our three tasks. Points were deducted for each move.
[leaderboard here]
Get Involved
- Want to help create new levels and environments for AI evaluation/training?
- Interested in fine tuning open-weights models to have better spatial reasoning and computer use capabilities?
- Are you an educator looking for a great hands-on way to test and improve AI in the classroom?
- Work at a frontier lab and are looking for training data or RL environments?
If you answered "yes" to any of the above, send us an email and we'll get back to you very quickly!